Introduction
We have structured the problem to make a churn prediction model that can be used for live services. The purpose of churn prediction is to get additional benefits through churn prevention. Therefore, to meet this purpose, we have created the problem by considering the following factors:
- Churn definition
Unlike telecommunication services [2], online game services cannot define an explicit deregistration as a churn. According to our analysis, deregistration users are no more than 1% of the long-term unconnected users who are assumed to have left the game service. Therefore, the long-term unconnected state should be redefined as a churn.
Furthermore, users of PC online games have a weekly cycle of play patterns. For example, while there are users who access daily, there are many users who access only on weekends. Therefore, even if a user does not play a game for a few days or weeks, we should not define that the user has left. Whereas, if we define the too long unconnected state as a churn, we cannot address churning users promptly because it will take too long to determine whether or not users have left.
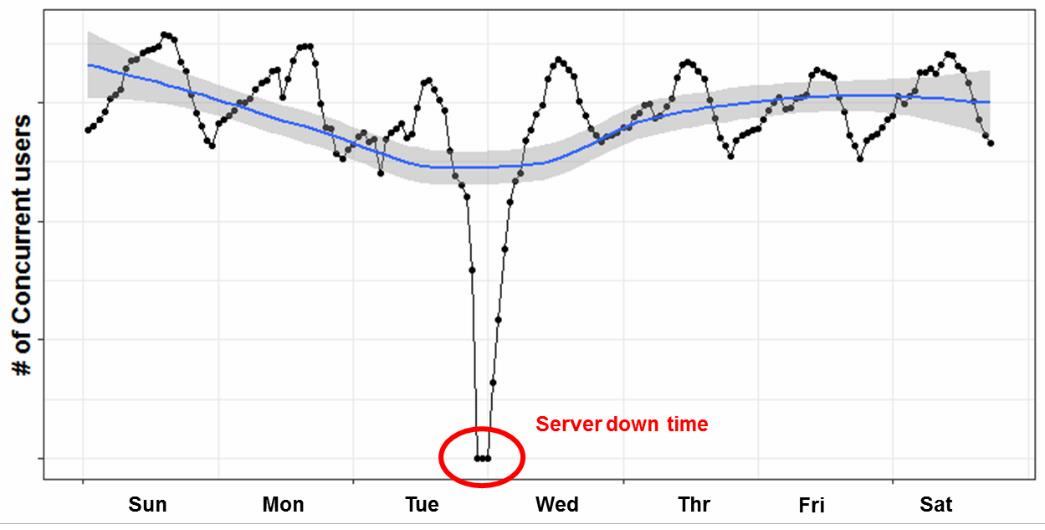
Fig.1 Time series of concurrent users for one week – there are daily and weekly cyclic patterns
Consequently, we have defined a user who does not play a game for more than five weeks as a churn to resolve the trade-off problem. Considering the weekly pattern, we check whether or not users left on every Wednesday. The reason is that our game service has weekly shutdown for contents updates and server maintenance on Wednesday morning (See Figure 1).
- Prediction targets
To benefit from a churn prevention, we should target users who are profitable. Unsurprisingly, not all users who play online games really benefit the game company. Many of them play a game for just short time rather than trying to enjoy the game genuinely. Furthermore, there are users who adversely affect the service [1].
We excluded these light playing users or malicious users when constructing data for churn prediction modeling. Therefore, most of the users provided by the problem are users who are highly loyal or with a charge of more than a certain amount.
- Prediction point
The best way to predict churning is to detect the behavior of the user just before leaving (e.g., delete the character). However, this is not a meaningful prediction. In order for actual predictions to be meaningful, it should be possible to predict with sufficient time to take action to turn the customers’ mind that is expected to leave.
Of course, if the duration of the predicted time and the actual leaving time is too long, it becomes difficult to detect the churn signal. Conversely, if this period is too short, we would have no sense of any action to turn their minds away, even if they accurately detected the actual churning user.
We thought it would take at least three weeks before departure to be effective. So, when constructing the data, we extracted the game logs up to three weeks before the actual departure.

- Survival analysis
While churn prediction is itself well worthwhile, the model’s value will be higher if the model can predict when users leave specifically. Consequently, we made the additional problem about survival analysis. To this end, we added survival time to the labeled data for training set.
There are censoring data because we can only check for observable periods. We added a ‘+’ sign after survival periods for right-censoring data to distinguish censoring data from churning data.
- Concept drift
Various operational issues arise when applying the prediction model to the live service. Concept drift is one of the most representative issues [3]. Models that have high performance during the modeling period, but whose performance declines over time, are less valuable due to the maintenance cost than the robust model, even if the performance is not very high at first.
Consequently, we provided two test sets to evaluate the performance of a model. One set is data near the training data, and the other is the data after the rapid change in the business model. So we will evaluate the performance of each of two test sets and then use the harmonic mean of these two values as the final evaluation result.
‘Blade & Soul’ had subscription model but switched to free-to-play in December 2016. Consequently, as the business model changes, users’ play patterns may change. Of course, we have already checked that the change is not overly large through the postmortem analysis. Therefore, we believe that the model created for the training data can be still meaningful for test sets in free-to-play. Consequently, we expect to be able to create a robust model that will allow for this change.
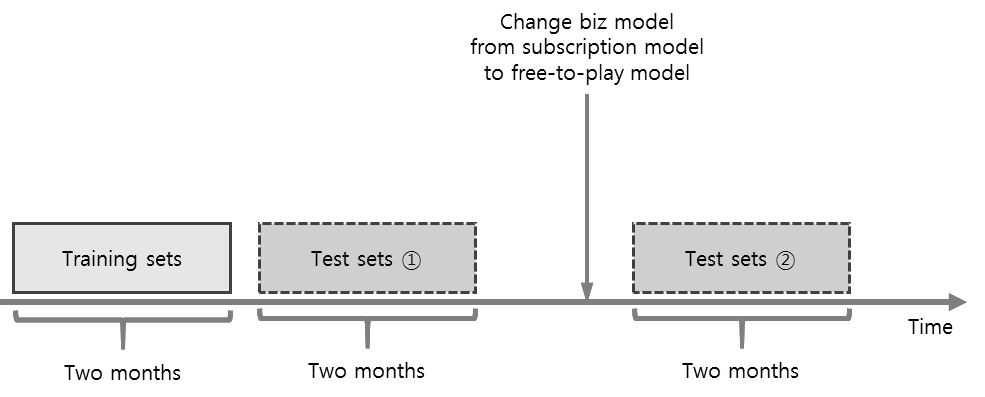
Furthermore, we do not restrict the approach to address the concept drift by using the test sets as unlabeled training sets. If you take this approach, it would be a great help if you share your approach with us.
References
[1] Lee, Eunjo, et al. “You are a game bot!: uncovering game bots in MMORPGs via self-similarity in the wild.” Proc. Netw. Distrib. Syst. Secur. Symp.(NDSS). 2016.
[2] Mozer, Michael C., et al. “Predicting subscriber dissatisfaction and improving retention in the wireless
telecommunications industry.” IEEE Transactions on neural networks 11.3 (2000): 690-696.
[3] Tsymbal, Alexey. “The problem of concept drift: definitions and related work.” Computer Science Department, Trinity College Dublin 106.2 (2004).